Multi-Timescale Prediction
Before we start
This tutorial is rendered from a Jupyter notebook that is hosted on GitHub. If you want to run the code yourself, you can find the notebook and configuration files here.
To be able to run this notebook locally, you need to download the publicly available CAMELS US rainfall-runoff dataset and a publicly available extensions for hourly forcing and streamflow data. See the Data Prerequisites Tutorial for a detailed description on where to download the data and how to structure your local dataset folder. Note the special section with additional requirements for this tutorial.
This notebook showcases some ways to use the MTS-LSTM from our recent publication to generate predictions at multiple timescales: “Rainfall-Runoff Prediction at Multiple Timescales with a Single Long Short-Term Memory Network”.
Let’s assume we have a set of daily meteorological forcing variables and a set of hourly variables, and we want to generate daily and hourly discharge predictions. Now, we could just go and train two separate LSTMs: One on the daily forcings to generate daily predictions, and one on the hourly forcings to generate hourly ones. One problem with this approach: It takes a lot of time, even if you run it on a GPU. The reason is that the hourly model would crunch through a years’ worth of hourly data to predict a single hour (assuming we provide the model input sequences with the same look-back that we usually use with daily data). That’s \(365 \times 24 = 8760\) time steps to process for each prediction. Not only does this take ages to train and evaluate, but also the training procedure becomes quite unstable and it is theoretically really hard for the model to learn dependencies over that many time steps. What’s more, the daily and hourly predictions might end up being inconsistent, because the two models are entirely unrelated.
MTS-LSTM
MTS-LSTM solves these issues: We can use a single model to predict both hourly and daily discharge, and with some tricks, we can push the model toward predictions that are consistent across timescales.
The Intuition
The basic idea of MTS-LSTM is this: we can process time steps that are far in the past at lower temporal resolution. As an example, to predict discharge of September 10 9:00am, we’ll certainly need fine-grained data for the previous few days or weeks. We might also need information from several months ago, but we probably don’t need to know if it rained at 6:00am or 7:00am on May 15. It’s just so long ago that the fine resolution doesn’t matter anymore.
How it’s Implemented
The MTS-LSTM architecture follows this principle: To predict today’s daily and hourly dicharge, we start feeding daily meteorological information from up to a year ago into the LSTM. At some point, say 14 days before today, we split our processing into two branches:
The first branch just keeps going with daily inputs until it outputs today’s daily prediction. So far, there’s no difference to normal daily-only prediction.
The second branch is where it gets interesting: We take the LSTM state from 14 days before today, apply a linear transformation to it, and then use the resulting states as the starting point for another LSTM, which we feed the 14 days of hourly data until it generates today’s 24 hourly predictions.
Thus, in a single forward pass through the MTS-LSTM, we’ve generated both daily and hourly predictions.
If you prefer visualizations, here’s what the architecture looks like:
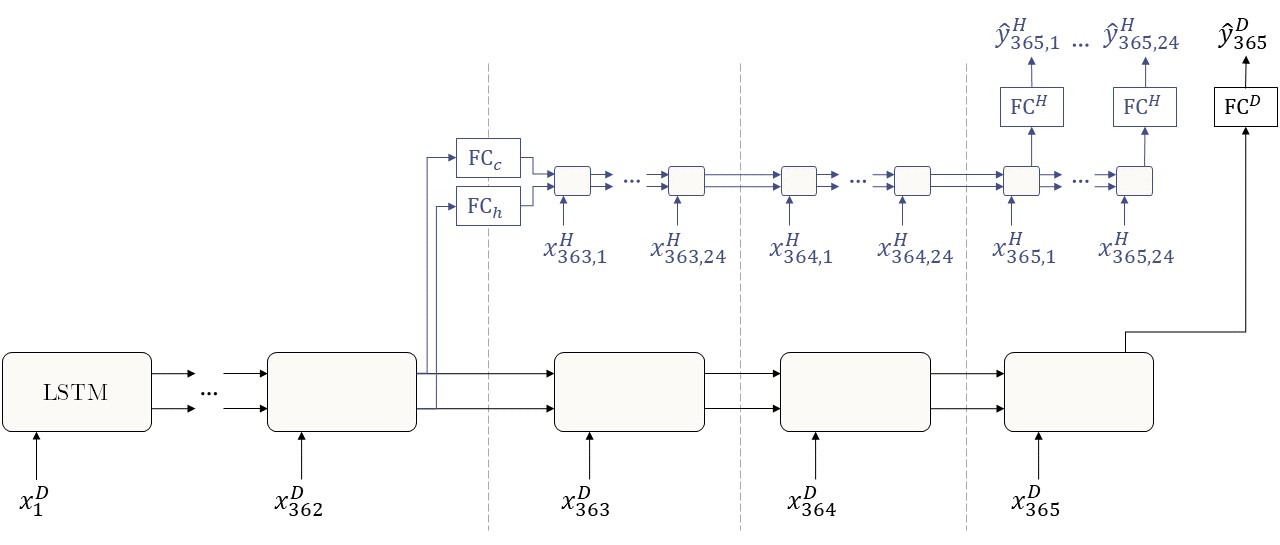
You can see how the first 362 input steps are done at the daily timescale (the visualization uses 362 days, but in reality this is a tunable hyperparameter). Starting with day 363, two things happen:
The daily LSTM just keeps going with daily inputs.
We take the hidden and cell states from day 362 and pass them through a linear layer. Starting with these new states, the hourly LSTM begins processing hourly inputs.
Finally, we pass the LSTMs’ outputs through a linear output layer (\(\text{FC}^H\) and \(\text{FC}^D\)) and get our predictions.
Some Variations
Now that we have this model, we can think of a few variations:
Because the MTS-LSTM has an individual branch for each timescale, we can actually use a different forcings product at each timescale (e.g., daily Daymet and hourly NLDAS). Going even further, we can use multiple sets of forcings at each timescale (e.g., daily Daymet and Maurer, but only hourly NLDAS). This can improve predictions a lot (see Kratzert et al., 2020).
We could also use the same LSTM weights in all timescales’ branches. We call this model the shared MTS-LSTM (sMTS-LSTM). In our results, the shared version generated slightly better predictions if all we have is one forcings dataset. The drawback is that the model doesn’t support per-timescale forcings. Thus, if you have several forcings datasets, you’ll most likely get better predictions if you use MTS-LSTM (non-shared) and leverage all your datasets.
We can link the daily and hourly predictions during training to nudge the model towards predictions that are consistent across timescales. We do this by means of a regularization of the loss function that increases the loss if the average daily prediction aggregated from hourly predictions does not match the daily prediction.
Using MTS-LSTM
So, let’s look at some code to train and evaluate an MTS-LSTM! The following code uses the NeuralHydrology package to train an MTS-LSTM on daily and hourly discharge prediction. For the sake of a quick example, we’ll train our model on just a single basin. When you actually care about the quality of your predictions, you’ll generally get much better model performance when training on hundreds of basins.
[1]:
from pathlib import Path
import matplotlib.pyplot as plt
import torch
from neuralhydrology.evaluation import metrics, get_tester
from neuralhydrology.nh_run import start_run
from neuralhydrology.utils.config import Config
Every experiment in NeuralHydrology uses a configuration file that specifies its setup. The config file for this example is called 1_basin.yml and can be found in the same directory as this notebook file. Let’s look at some of the relevant configuration options:
[2]:
run_config = Config(Path("1_basin.yml"))
print('model:\t\t', run_config.model)
print('use_frequencies:', run_config.use_frequencies)
print('seq_length:\t', run_config.seq_length)
model: mtslstm
use_frequencies: ['1h', '1D']
seq_length: {'1D': 365, '1h': 336}
model is obvious: We want to use the MTS-LSTM. For the sMTS-LSTM, we’d set run_config.shared_mtslstm = True. In use_frequencies, we specify the timescales we want to predict. In seq_length, we specify for each timescale the look-back window. Here, we’ll start with 365 days look-back, and the hourly LSTM branch will get the last 14 days (\(336/24 = 14\)) at an hourly resolution.
As we’re using the MTS-LSTM (and not sMTS-LSTM), we can use different input variables at each frequency. Here, we use Maurer and Daymet as daily inputs, while the hourly model component uses NLDAS, Maurer, and Daymet. Note that even though Daymet and Maurer are daily products, we can use them to support the hourly predictions.
[3]:
print('dynamic_inputs:')
run_config.dynamic_inputs
dynamic_inputs:
[3]:
{'1D': ['prcp(mm/day)_daymet',
'srad(W/m2)_daymet',
'tmax(C)_daymet',
'tmin(C)_daymet',
'vp(Pa)_daymet'],
'1h': ['convective_fraction_nldas_hourly',
'longwave_radiation_nldas_hourly',
'potential_energy_nldas_hourly',
'potential_evaporation_nldas_hourly',
'pressure_nldas_hourly',
'shortwave_radiation_nldas_hourly',
'specific_humidity_nldas_hourly',
'temperature_nldas_hourly',
'total_precipitation_nldas_hourly',
'wind_u_nldas_hourly',
'wind_v_nldas_hourly',
'prcp(mm/day)_daymet',
'srad(W/m2)_daymet',
'tmax(C)_daymet',
'tmin(C)_daymet',
'vp(Pa)_daymet']}
Training
We start model training of our single-basin toy example with start_run.
Note
The config file assumes that the CAMELS US dataset is stored under
data/CAMELS_US(relative to the main directory of this repository) or a symbolic link exists at this location. Make sure that this folder contains the required subdirectoriesbasin_mean_forcing,usgs_streamflow, andhourly. If your data is stored at a different location and you can’t or don’t want to create a symbolic link, you will need to change thedata_dirargument in the1_basin.ymlconfig file that is located in the same directory as this notebook.By default, the config (
1_basin.yml) assumes that you have a CUDA-capable NVIDIA GPU (see config argumentdevice). In case you don’t have any or you have one but one to train on the CPU, you can either change the config argument todevice: cpuor passgpu=-1to thestart_run()function.If you want to train on MacOS devices with Metal programming framework which enables high-performance training on GPU for MacOS, change the config argument to
device: mpsand don’t pass thegpuargument to thestart_run()function.
[4]:
# by default we assume that you have at least one CUDA-capable NVIDIA GPU or MacOS with Metal support
if torch.cuda.is_available() or torch.backends.mps.is_available():
start_run(config_file=Path("1_basin.yml"))
# fall back to CPU-only mode
else:
start_run(config_file=Path("1_basin.yml"), gpu=-1)
2025-02-28 09:26:14,530: Logging to /home/gauch/Documents/neuralhydrology/neuralhydrology/examples/04-Multi-Timescale/runs/test_run_2802_092614/output.log initialized.
2025-02-28 09:26:14,531: ### Folder structure created at /home/gauch/Documents/neuralhydrology/neuralhydrology/examples/04-Multi-Timescale/runs/test_run_2802_092614
2025-02-28 09:26:14,531: ### Run configurations for test_run
2025-02-28 09:26:14,531: experiment_name: test_run
2025-02-28 09:26:14,531: use_frequencies: ['1h', '1D']
2025-02-28 09:26:14,532: train_basin_file: 1_basin.txt
2025-02-28 09:26:14,532: validation_basin_file: 1_basin.txt
2025-02-28 09:26:14,533: test_basin_file: 1_basin.txt
2025-02-28 09:26:14,533: train_start_date: 1999-10-01 00:00:00
2025-02-28 09:26:14,533: train_end_date: 2008-09-30 00:00:00
2025-02-28 09:26:14,533: validation_start_date: 1996-10-01 00:00:00
2025-02-28 09:26:14,534: validation_end_date: 1999-09-30 00:00:00
2025-02-28 09:26:14,534: test_start_date: 1989-10-01 00:00:00
2025-02-28 09:26:14,534: test_end_date: 1996-09-30 00:00:00
2025-02-28 09:26:14,534: device: cpu
2025-02-28 09:26:14,534: validate_every: 5
2025-02-28 09:26:14,535: validate_n_random_basins: 1
2025-02-28 09:26:14,535: metrics: ['NSE']
2025-02-28 09:26:14,535: model: mtslstm
2025-02-28 09:26:14,535: shared_mtslstm: False
2025-02-28 09:26:14,535: transfer_mtslstm_states: {'h': 'linear', 'c': 'linear'}
2025-02-28 09:26:14,536: head: regression
2025-02-28 09:26:14,536: output_activation: linear
2025-02-28 09:26:14,536: hidden_size: 20
2025-02-28 09:26:14,536: initial_forget_bias: 3
2025-02-28 09:26:14,536: output_dropout: 0.4
2025-02-28 09:26:14,537: optimizer: Adam
2025-02-28 09:26:14,537: loss: MSE
2025-02-28 09:26:14,537: regularization: ['tie_frequencies']
2025-02-28 09:26:14,537: learning_rate: {0: 0.01, 30: 0.005, 40: 0.001}
2025-02-28 09:26:14,537: batch_size: 256
2025-02-28 09:26:14,538: epochs: 50
2025-02-28 09:26:14,538: clip_gradient_norm: 1
2025-02-28 09:26:14,538: predict_last_n: {'1D': 1, '1h': 24}
2025-02-28 09:26:14,538: seq_length: {'1D': 365, '1h': 336}
2025-02-28 09:26:14,538: num_workers: 8
2025-02-28 09:26:14,539: log_interval: 5
2025-02-28 09:26:14,540: log_tensorboard: False
2025-02-28 09:26:14,541: log_n_figures: 0
2025-02-28 09:26:14,541: save_weights_every: 1
2025-02-28 09:26:14,541: dataset: hourly_camels_us
2025-02-28 09:26:14,542: data_dir: ../../data/CAMELS_US
2025-02-28 09:26:14,542: forcings: ['nldas_hourly', 'daymet']
2025-02-28 09:26:14,542: dynamic_inputs: {'1D': ['prcp(mm/day)_daymet', 'srad(W/m2)_daymet', 'tmax(C)_daymet', 'tmin(C)_daymet', 'vp(Pa)_daymet'], '1h': ['convective_fraction_nldas_hourly', 'longwave_radiation_nldas_hourly', 'potential_energy_nldas_hourly', 'potential_evaporation_nldas_hourly', 'pressure_nldas_hourly', 'shortwave_radiation_nldas_hourly', 'specific_humidity_nldas_hourly', 'temperature_nldas_hourly', 'total_precipitation_nldas_hourly', 'wind_u_nldas_hourly', 'wind_v_nldas_hourly', 'prcp(mm/day)_daymet', 'srad(W/m2)_daymet', 'tmax(C)_daymet', 'tmin(C)_daymet', 'vp(Pa)_daymet']}
2025-02-28 09:26:14,543: target_variables: ['qobs_mm_per_hour']
2025-02-28 09:26:14,543: clip_targets_to_zero: ['qobs_mm_per_hour']
2025-02-28 09:26:14,543: number_of_basins: 1
2025-02-28 09:26:14,544: run_dir: /home/gauch/Documents/neuralhydrology/neuralhydrology/examples/04-Multi-Timescale/runs/test_run_2802_092614
2025-02-28 09:26:14,544: train_dir: /home/gauch/Documents/neuralhydrology/neuralhydrology/examples/04-Multi-Timescale/runs/test_run_2802_092614/train_data
2025-02-28 09:26:14,544: img_log_dir: /home/gauch/Documents/neuralhydrology/neuralhydrology/examples/04-Multi-Timescale/runs/test_run_2802_092614/img_log
2025-02-28 09:26:14,546: ### Device cpu will be used for training
2025-02-28 09:26:14,547: Loading basin data into xarray data set.
100%|██████████| 1/1 [00:00<00:00, 3.11it/s]
2025-02-28 09:26:14,884: Create lookup table and convert to pytorch tensor
100%|██████████| 1/1 [00:00<00:00, 1.07it/s]
2025-02-28 09:26:15,827: No specific hidden size for frequencies are specified. Same hidden size is used for all.
# Epoch 1: 100%|██████████| 11/11 [00:01<00:00, 9.18it/s, Loss: 0.5111]
2025-02-28 09:26:17,682: Epoch 1 average loss: avg_loss: 0.76642, avg_tie_frequencies: 0.09031, avg_total_loss: 0.85673
# Epoch 2: 100%|██████████| 11/11 [00:01<00:00, 9.39it/s, Loss: 0.4323]
2025-02-28 09:26:18,858: Epoch 2 average loss: avg_loss: 0.61432, avg_tie_frequencies: 0.06547, avg_total_loss: 0.67979
# Epoch 3: 100%|██████████| 11/11 [00:01<00:00, 9.46it/s, Loss: 0.3657]
2025-02-28 09:26:20,025: Epoch 3 average loss: avg_loss: 0.53565, avg_tie_frequencies: 0.06568, avg_total_loss: 0.60133
# Epoch 4: 100%|██████████| 11/11 [00:01<00:00, 9.36it/s, Loss: 0.4308]
2025-02-28 09:26:21,205: Epoch 4 average loss: avg_loss: 0.45822, avg_tie_frequencies: 0.07432, avg_total_loss: 0.53254
# Epoch 5: 100%|██████████| 11/11 [00:01<00:00, 9.93it/s, Loss: 0.4129]
2025-02-28 09:26:22,317: Epoch 5 average loss: avg_loss: 0.40461, avg_tie_frequencies: 0.07921, avg_total_loss: 0.48382
# Validation: 100%|██████████| 1/1 [00:00<00:00, 1.65it/s]
2025-02-28 09:26:22,927: Epoch 5 average validation loss: 0.32148 -- Median validation metrics: avg_loss: 0.26466, avg_tie_frequencies: 0.05683, NSE_1h: 0.56244, NSE_1D: 0.52942
# Epoch 6: 100%|██████████| 11/11 [00:01<00:00, 10.40it/s, Loss: 0.2912]
2025-02-28 09:26:23,987: Epoch 6 average loss: avg_loss: 0.34779, avg_tie_frequencies: 0.07290, avg_total_loss: 0.42069
# Epoch 7: 100%|██████████| 11/11 [00:01<00:00, 9.79it/s, Loss: 0.2493]
2025-02-28 09:26:25,114: Epoch 7 average loss: avg_loss: 0.32660, avg_tie_frequencies: 0.07925, avg_total_loss: 0.40584
# Epoch 8: 100%|██████████| 11/11 [00:01<00:00, 9.38it/s, Loss: 0.3583]
2025-02-28 09:26:26,292: Epoch 8 average loss: avg_loss: 0.29944, avg_tie_frequencies: 0.07566, avg_total_loss: 0.37509
# Epoch 9: 100%|██████████| 11/11 [00:01<00:00, 9.04it/s, Loss: 0.3152]
2025-02-28 09:26:27,514: Epoch 9 average loss: avg_loss: 0.27751, avg_tie_frequencies: 0.07218, avg_total_loss: 0.34969
# Epoch 10: 100%|██████████| 11/11 [00:01<00:00, 7.26it/s, Loss: 0.4087]
2025-02-28 09:26:29,035: Epoch 10 average loss: avg_loss: 0.27042, avg_tie_frequencies: 0.07373, avg_total_loss: 0.34416
# Validation: 100%|██████████| 1/1 [00:00<00:00, 5.59it/s]
2025-02-28 09:26:29,220: Epoch 10 average validation loss: 0.35439 -- Median validation metrics: avg_loss: 0.27578, avg_tie_frequencies: 0.07861, NSE_1h: 0.53507, NSE_1D: 0.63250
# Epoch 11: 100%|██████████| 11/11 [00:01<00:00, 7.10it/s, Loss: 0.2630]
2025-02-28 09:26:30,772: Epoch 11 average loss: avg_loss: 0.25453, avg_tie_frequencies: 0.07043, avg_total_loss: 0.32497
# Epoch 12: 100%|██████████| 11/11 [00:01<00:00, 7.15it/s, Loss: 0.3771]
2025-02-28 09:26:32,317: Epoch 12 average loss: avg_loss: 0.23633, avg_tie_frequencies: 0.07723, avg_total_loss: 0.31356
# Epoch 13: 100%|██████████| 11/11 [00:01<00:00, 7.64it/s, Loss: 0.3553]
2025-02-28 09:26:33,763: Epoch 13 average loss: avg_loss: 0.23810, avg_tie_frequencies: 0.07281, avg_total_loss: 0.31091
# Epoch 14: 100%|██████████| 11/11 [00:01<00:00, 6.74it/s, Loss: 0.1604]
2025-02-28 09:26:35,402: Epoch 14 average loss: avg_loss: 0.22196, avg_tie_frequencies: 0.06841, avg_total_loss: 0.29037
# Epoch 15: 100%|██████████| 11/11 [00:01<00:00, 7.33it/s, Loss: 0.3782]
2025-02-28 09:26:36,910: Epoch 15 average loss: avg_loss: 0.21995, avg_tie_frequencies: 0.07035, avg_total_loss: 0.29031
# Validation: 100%|██████████| 1/1 [00:00<00:00, 5.34it/s]
2025-02-28 09:26:37,103: Epoch 15 average validation loss: 0.34646 -- Median validation metrics: avg_loss: 0.24369, avg_tie_frequencies: 0.10277, NSE_1h: 0.56137, NSE_1D: 0.67126
# Epoch 16: 100%|██████████| 11/11 [00:01<00:00, 7.60it/s, Loss: 0.2190]
2025-02-28 09:26:38,553: Epoch 16 average loss: avg_loss: 0.21573, avg_tie_frequencies: 0.07074, avg_total_loss: 0.28646
# Epoch 17: 100%|██████████| 11/11 [00:01<00:00, 7.18it/s, Loss: 0.4095]
2025-02-28 09:26:40,092: Epoch 17 average loss: avg_loss: 0.20412, avg_tie_frequencies: 0.06404, avg_total_loss: 0.26816
# Epoch 18: 100%|██████████| 11/11 [00:01<00:00, 7.36it/s, Loss: 0.1752]
2025-02-28 09:26:41,594: Epoch 18 average loss: avg_loss: 0.19208, avg_tie_frequencies: 0.07447, avg_total_loss: 0.26655
# Epoch 19: 100%|██████████| 11/11 [00:01<00:00, 6.94it/s, Loss: 0.2641]
2025-02-28 09:26:43,186: Epoch 19 average loss: avg_loss: 0.19927, avg_tie_frequencies: 0.06836, avg_total_loss: 0.26763
# Epoch 20: 100%|██████████| 11/11 [00:01<00:00, 7.84it/s, Loss: 0.2979]
2025-02-28 09:26:44,594: Epoch 20 average loss: avg_loss: 0.19993, avg_tie_frequencies: 0.07241, avg_total_loss: 0.27234
# Validation: 100%|██████████| 1/1 [00:00<00:00, 5.24it/s]
2025-02-28 09:26:44,791: Epoch 20 average validation loss: 0.32061 -- Median validation metrics: avg_loss: 0.25326, avg_tie_frequencies: 0.06735, NSE_1h: 0.61062, NSE_1D: 0.69064
# Epoch 21: 100%|██████████| 11/11 [00:01<00:00, 8.16it/s, Loss: 0.2610]
2025-02-28 09:26:46,141: Epoch 21 average loss: avg_loss: 0.18019, avg_tie_frequencies: 0.07186, avg_total_loss: 0.25205
# Epoch 22: 100%|██████████| 11/11 [00:01<00:00, 7.40it/s, Loss: 0.4465]
2025-02-28 09:26:47,634: Epoch 22 average loss: avg_loss: 0.17289, avg_tie_frequencies: 0.06351, avg_total_loss: 0.23640
# Epoch 23: 100%|██████████| 11/11 [00:01<00:00, 7.59it/s, Loss: 0.2056]
2025-02-28 09:26:49,090: Epoch 23 average loss: avg_loss: 0.16348, avg_tie_frequencies: 0.06313, avg_total_loss: 0.22662
# Epoch 24: 100%|██████████| 11/11 [00:01<00:00, 7.48it/s, Loss: 0.1699]
2025-02-28 09:26:50,567: Epoch 24 average loss: avg_loss: 0.15688, avg_tie_frequencies: 0.06121, avg_total_loss: 0.21810
# Epoch 25: 100%|██████████| 11/11 [00:01<00:00, 7.16it/s, Loss: 0.1532]
2025-02-28 09:26:52,112: Epoch 25 average loss: avg_loss: 0.15894, avg_tie_frequencies: 0.06730, avg_total_loss: 0.22625
# Validation: 100%|██████████| 1/1 [00:00<00:00, 6.48it/s]
2025-02-28 09:26:52,272: Epoch 25 average validation loss: 0.34219 -- Median validation metrics: avg_loss: 0.23545, avg_tie_frequencies: 0.10674, NSE_1h: 0.64719, NSE_1D: 0.68902
# Epoch 26: 100%|██████████| 11/11 [00:01<00:00, 7.33it/s, Loss: 0.2746]
2025-02-28 09:26:53,776: Epoch 26 average loss: avg_loss: 0.16565, avg_tie_frequencies: 0.06860, avg_total_loss: 0.23425
# Epoch 27: 100%|██████████| 11/11 [00:01<00:00, 7.59it/s, Loss: 0.2889]
2025-02-28 09:26:55,232: Epoch 27 average loss: avg_loss: 0.16506, avg_tie_frequencies: 0.06311, avg_total_loss: 0.22817
# Epoch 28: 100%|██████████| 11/11 [00:01<00:00, 7.29it/s, Loss: 0.2074]
2025-02-28 09:26:56,747: Epoch 28 average loss: avg_loss: 0.15574, avg_tie_frequencies: 0.05586, avg_total_loss: 0.21160
# Epoch 29: 100%|██████████| 11/11 [00:01<00:00, 7.02it/s, Loss: 0.1939]
2025-02-28 09:26:58,320: Epoch 29 average loss: avg_loss: 0.14888, avg_tie_frequencies: 0.06093, avg_total_loss: 0.20981
2025-02-28 09:26:58,324: Setting learning rate to 0.005
# Epoch 30: 100%|██████████| 11/11 [00:01<00:00, 7.35it/s, Loss: 0.1977]
2025-02-28 09:26:59,823: Epoch 30 average loss: avg_loss: 0.14118, avg_tie_frequencies: 0.05111, avg_total_loss: 0.19229
# Validation: 100%|██████████| 1/1 [00:00<00:00, 5.12it/s]
2025-02-28 09:27:00,024: Epoch 30 average validation loss: 0.33362 -- Median validation metrics: avg_loss: 0.22696, avg_tie_frequencies: 0.10667, NSE_1h: 0.66981, NSE_1D: 0.69439
# Epoch 31: 100%|██████████| 11/11 [00:01<00:00, 7.72it/s, Loss: 0.2557]
2025-02-28 09:27:01,452: Epoch 31 average loss: avg_loss: 0.13553, avg_tie_frequencies: 0.05115, avg_total_loss: 0.18668
# Epoch 32: 100%|██████████| 11/11 [00:01<00:00, 7.49it/s, Loss: 0.2389]
2025-02-28 09:27:02,928: Epoch 32 average loss: avg_loss: 0.13541, avg_tie_frequencies: 0.05224, avg_total_loss: 0.18764
# Epoch 33: 100%|██████████| 11/11 [00:01<00:00, 7.21it/s, Loss: 0.1214]
2025-02-28 09:27:04,458: Epoch 33 average loss: avg_loss: 0.12837, avg_tie_frequencies: 0.05379, avg_total_loss: 0.18216
# Epoch 34: 100%|██████████| 11/11 [00:01<00:00, 7.20it/s, Loss: 0.2436]
2025-02-28 09:27:05,991: Epoch 34 average loss: avg_loss: 0.13556, avg_tie_frequencies: 0.05527, avg_total_loss: 0.19083
# Epoch 35: 100%|██████████| 11/11 [00:01<00:00, 7.41it/s, Loss: 0.2554]
2025-02-28 09:27:07,482: Epoch 35 average loss: avg_loss: 0.13029, avg_tie_frequencies: 0.05603, avg_total_loss: 0.18632
# Validation: 100%|██████████| 1/1 [00:00<00:00, 5.60it/s]
2025-02-28 09:27:07,667: Epoch 35 average validation loss: 0.31536 -- Median validation metrics: avg_loss: 0.21185, avg_tie_frequencies: 0.10350, NSE_1h: 0.68976, NSE_1D: 0.70399
# Epoch 36: 100%|██████████| 11/11 [00:01<00:00, 7.10it/s, Loss: 0.1625]
2025-02-28 09:27:09,219: Epoch 36 average loss: avg_loss: 0.12710, avg_tie_frequencies: 0.05123, avg_total_loss: 0.17833
# Epoch 37: 100%|██████████| 11/11 [00:01<00:00, 7.15it/s, Loss: 0.1937]
2025-02-28 09:27:10,766: Epoch 37 average loss: avg_loss: 0.12643, avg_tie_frequencies: 0.05097, avg_total_loss: 0.17740
# Epoch 38: 100%|██████████| 11/11 [00:01<00:00, 7.60it/s, Loss: 0.1454]
2025-02-28 09:27:12,220: Epoch 38 average loss: avg_loss: 0.12745, avg_tie_frequencies: 0.05418, avg_total_loss: 0.18163
# Epoch 39: 100%|██████████| 11/11 [00:01<00:00, 7.31it/s, Loss: 0.1249]
2025-02-28 09:27:13,731: Epoch 39 average loss: avg_loss: 0.12265, avg_tie_frequencies: 0.05010, avg_total_loss: 0.17275
2025-02-28 09:27:13,735: Setting learning rate to 0.001
# Epoch 40: 100%|██████████| 11/11 [00:01<00:00, 7.25it/s, Loss: 0.1657]
2025-02-28 09:27:15,254: Epoch 40 average loss: avg_loss: 0.12030, avg_tie_frequencies: 0.05247, avg_total_loss: 0.17277
# Validation: 100%|██████████| 1/1 [00:00<00:00, 5.28it/s]
2025-02-28 09:27:15,449: Epoch 40 average validation loss: 0.29747 -- Median validation metrics: avg_loss: 0.20299, avg_tie_frequencies: 0.09448, NSE_1h: 0.70323, NSE_1D: 0.71584
# Epoch 41: 100%|██████████| 11/11 [00:01<00:00, 7.42it/s, Loss: 0.2346]
2025-02-28 09:27:16,935: Epoch 41 average loss: avg_loss: 0.12554, avg_tie_frequencies: 0.05114, avg_total_loss: 0.17668
# Epoch 42: 100%|██████████| 11/11 [00:01<00:00, 7.52it/s, Loss: 0.1341]
2025-02-28 09:27:18,403: Epoch 42 average loss: avg_loss: 0.11694, avg_tie_frequencies: 0.04744, avg_total_loss: 0.16438
# Epoch 43: 100%|██████████| 11/11 [00:01<00:00, 6.96it/s, Loss: 0.1283]
2025-02-28 09:27:19,990: Epoch 43 average loss: avg_loss: 0.11653, avg_tie_frequencies: 0.04712, avg_total_loss: 0.16365
# Epoch 44: 100%|██████████| 11/11 [00:02<00:00, 3.96it/s, Loss: 0.2351]
2025-02-28 09:27:22,774: Epoch 44 average loss: avg_loss: 0.12274, avg_tie_frequencies: 0.04782, avg_total_loss: 0.17055
# Epoch 45: 100%|██████████| 11/11 [00:03<00:00, 3.26it/s, Loss: 0.1362]
2025-02-28 09:27:26,164: Epoch 45 average loss: avg_loss: 0.11922, avg_tie_frequencies: 0.04534, avg_total_loss: 0.16456
# Validation: 100%|██████████| 1/1 [00:00<00:00, 2.83it/s]
2025-02-28 09:27:26,531: Epoch 45 average validation loss: 0.30023 -- Median validation metrics: avg_loss: 0.20181, avg_tie_frequencies: 0.09842, NSE_1h: 0.71333, NSE_1D: 0.70986
# Epoch 46: 100%|██████████| 11/11 [00:03<00:00, 3.45it/s, Loss: 0.1376]
2025-02-28 09:27:29,730: Epoch 46 average loss: avg_loss: 0.11522, avg_tie_frequencies: 0.04761, avg_total_loss: 0.16283
# Epoch 47: 100%|██████████| 11/11 [00:03<00:00, 3.42it/s, Loss: 0.1647]
2025-02-28 09:27:32,964: Epoch 47 average loss: avg_loss: 0.11956, avg_tie_frequencies: 0.04986, avg_total_loss: 0.16942
# Epoch 48: 100%|██████████| 11/11 [00:02<00:00, 3.67it/s, Loss: 0.1651]
2025-02-28 09:27:35,974: Epoch 48 average loss: avg_loss: 0.11397, avg_tie_frequencies: 0.04784, avg_total_loss: 0.16181
# Epoch 49: 100%|██████████| 11/11 [00:03<00:00, 3.62it/s, Loss: 0.1853]
2025-02-28 09:27:39,029: Epoch 49 average loss: avg_loss: 0.11663, avg_tie_frequencies: 0.04547, avg_total_loss: 0.16209
# Epoch 50: 100%|██████████| 11/11 [00:03<00:00, 3.60it/s, Loss: 0.1930]
2025-02-28 09:27:42,101: Epoch 50 average loss: avg_loss: 0.11225, avg_tie_frequencies: 0.05019, avg_total_loss: 0.16244
# Validation: 100%|██████████| 1/1 [00:00<00:00, 2.44it/s]
2025-02-28 09:27:42,523: Epoch 50 average validation loss: 0.30528 -- Median validation metrics: avg_loss: 0.20344, avg_tie_frequencies: 0.10184, NSE_1h: 0.71061, NSE_1D: 0.70854
Evaluation
Given the trained model, we can generate and evaluate its predictions. Since the folder name is created dynamically (including the date and time of the start of the run) you will need to change the run_dir argument according to your local directory name.
[6]:
run_dir = Path("runs/test_run_2802_092614") # you'll find this path in the output of the training above.
# create a tester instance and start evaluation
tester = get_tester(cfg=Config(run_dir / "config.yml"), run_dir=run_dir, period="test", init_model=True)
results = tester.evaluate(save_results=False, metrics=run_config.metrics)
results.keys()
2025-02-28 09:27:56,389: No specific hidden size for frequencies are specified. Same hidden size is used for all.
2025-02-28 09:27:56,398: Using the model weights from runs/test_run_2802_092614/model_epoch050.pt
# Evaluation: 100%|██████████| 1/1 [00:00<00:00, 1.68it/s]
[6]:
dict_keys(['01022500'])
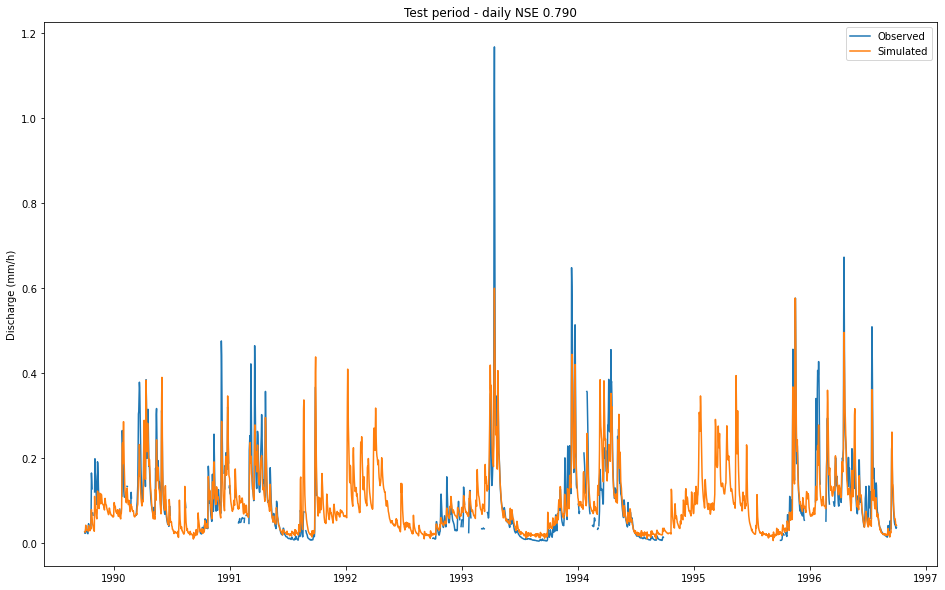
Let’s take a closer look at the predictions and do some plots, starting with the daily results. Note that units are mm/h even for daily values, since we predict daily averages.
[7]:
# extract observations and simulations
daily_qobs = results["01022500"]["1D"]["xr"]["qobs_mm_per_hour_obs"]
daily_qsim = results["01022500"]["1D"]["xr"]["qobs_mm_per_hour_sim"]
fig, ax = plt.subplots(figsize=(16,10))
ax.plot(daily_qobs["date"], daily_qobs, label="Observed")
ax.plot(daily_qsim["date"], daily_qsim, label="Simulated")
ax.legend()
ax.set_ylabel("Discharge (mm/h)")
ax.set_title(f"Test period - daily NSE {results['01022500']['1D']['NSE_1D']:.3f}")
# Calculate some metrics
values = metrics.calculate_all_metrics(daily_qobs.isel(time_step=-1), daily_qsim.isel(time_step=-1))
print("Daily metrics:")
for key, val in values.items():
print(f" {key}: {val:.3f}")
Daily metrics:
NSE: 0.784
MSE: 0.002
RMSE: 0.050
KGE: 0.795
Alpha-NSE: 0.829
Beta-KGE: 1.003
Beta-NSE: 0.003
Pearson-r: 0.887
FHV: -18.353
FMS: -15.840
FLV: 32.860
Peak-Timing: 0.625
Peak-MAPE: 25.023
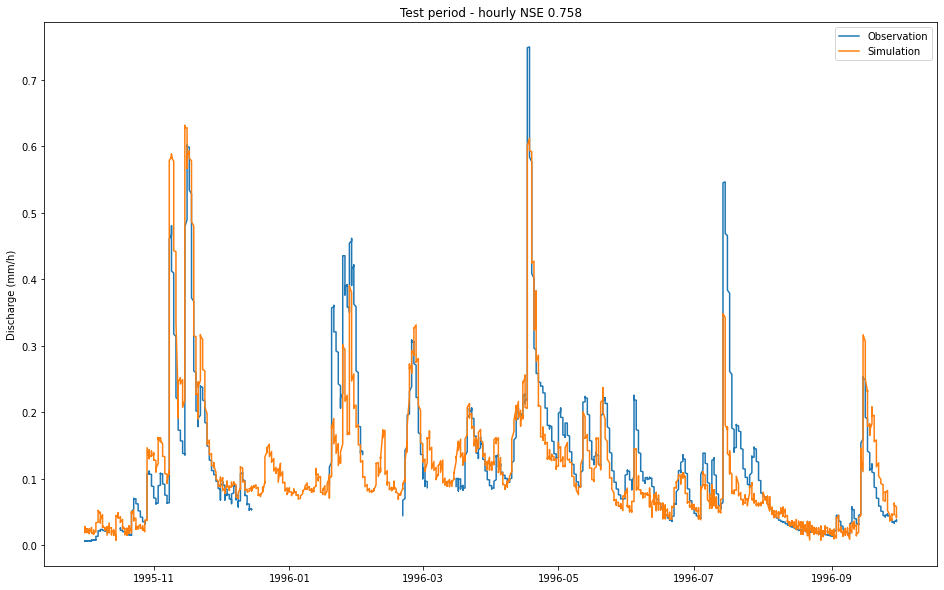
…and finally, let’s look more closely at the last few months’ hourly predictions:
[8]:
# extract a date slice of observations and simulations
hourly_xr = results["01022500"]["1h"]["xr"].sel(date=slice("10-1995", None))
# The hourly data is indexed with two indices: The date (in days) and the time_step (the hour within that day).
# As we want to get a continuous plot of several days' hours, we select all 24 hours of each day and then stack
# the two dimensions into one consecutive datetime dimension.
hourly_xr = hourly_xr.isel(time_step=slice(-24, None)).stack(datetime=['date', 'time_step'])
hourly_xr['datetime'] = hourly_xr.coords['date'] + hourly_xr.coords['time_step']
hourly_qobs = hourly_xr["qobs_mm_per_hour_obs"]
hourly_qsim = hourly_xr["qobs_mm_per_hour_sim"]
fig, ax = plt.subplots(figsize=(16,10))
ax.plot(hourly_qobs["datetime"], hourly_qobs, label="Observation")
ax.plot(hourly_qsim["datetime"], hourly_qsim, label="Simulation")
ax.set_ylabel("Discharge (mm/h)")
ax.set_title(f"Test period - hourly NSE {results['01022500']['1h']['NSE_1h']:.3f}")
_ = ax.legend()
[ ]: